-2.png?height=120&name=EDITED%20Logo%20Dark%20-%20Color%20(1)-2.png)
As the global leader in retail market intelligence, EDITED helps retailers increase margins, generate more sales, and drive better outcomes through AI driven market data, analytics, and research. Our AI (Artificial Intelligence) engine tracks billions of products and prices worldwide, capturing details from daily pricing shifts to care & compositions. But how does EDITED Market's data collection work?
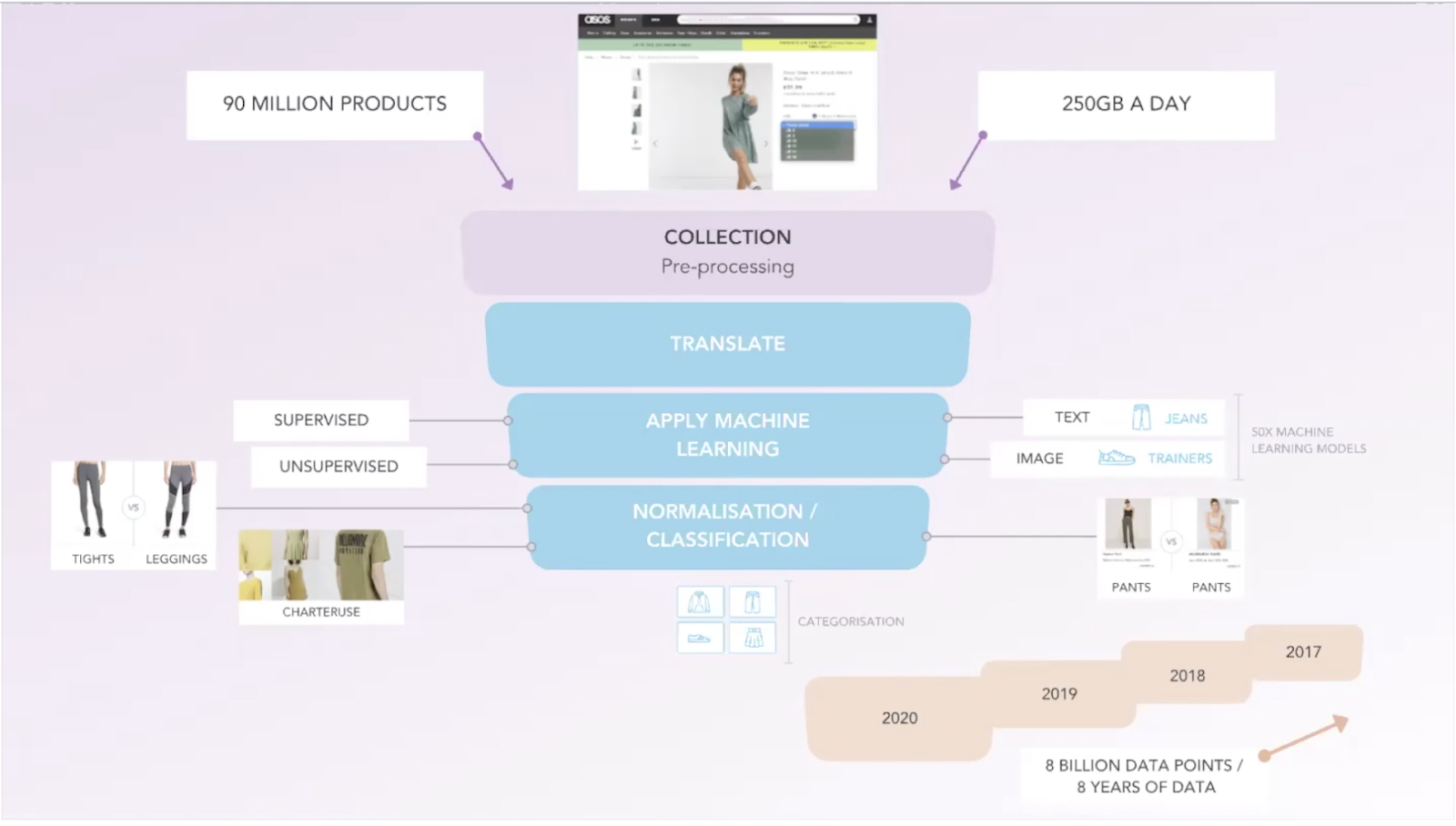
Interpreting the data is a 2-part process:
1. Collecting The Data
All of the data EDITED Market collects is publicly available ecommerce data. This means we do not track stock or sales data, as this is proprietary information of the retailer. We do track details such as product name, price + price changes, SKU availability, care & composition, details, launch dates, and images.
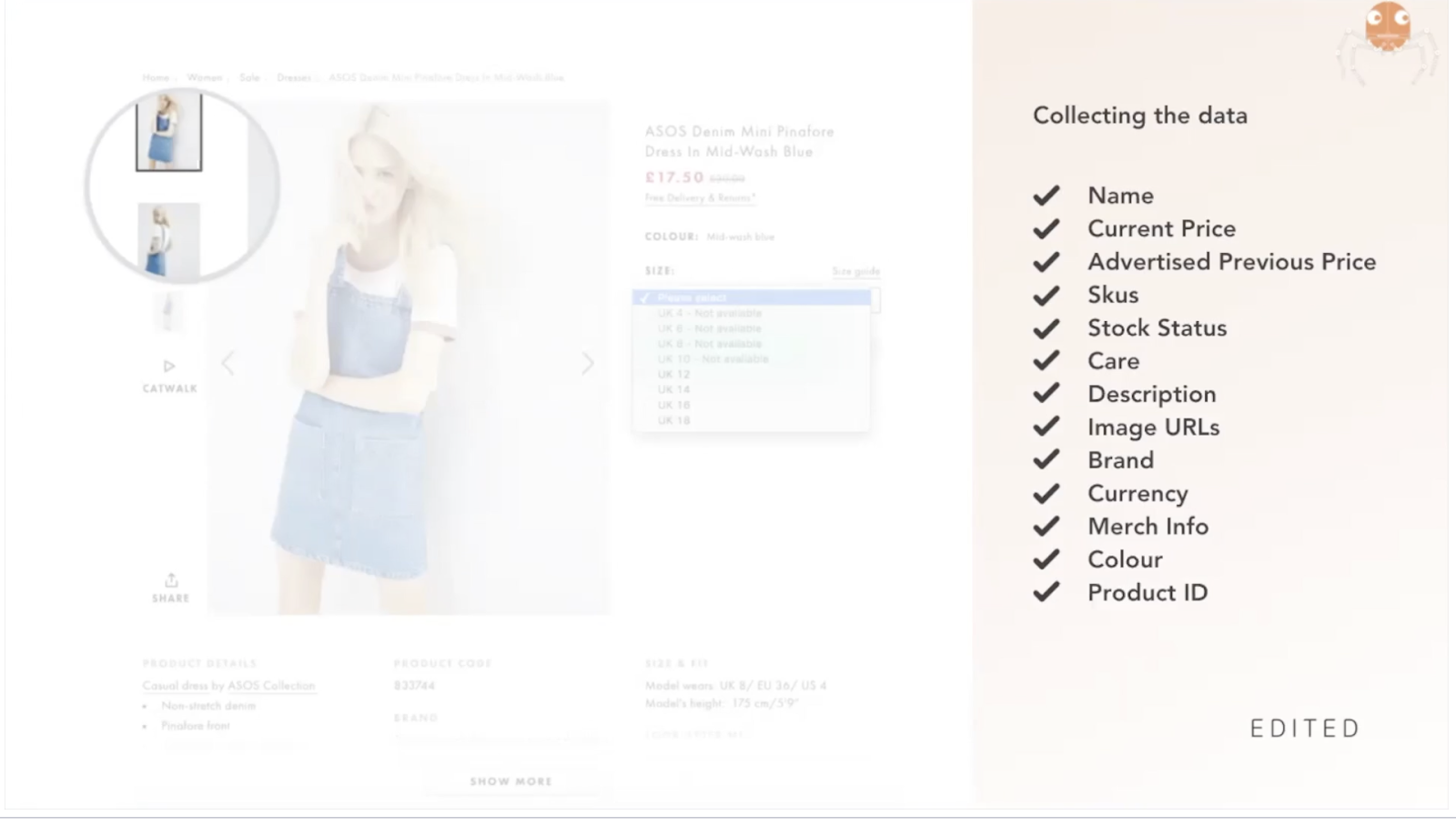
Our data trackers are designed to simulate a shopper, picking up the key product details previously mentioned from each website up to every 24 hours. For each retailer's individual regional site, a separate unique tracker is built. Every tracker is bespoke for each website's structure, individually built in house by our Product & Engineering team, and rigorously tested for accuracy.
A tracker alert system frequently monitors tracker health and updates our data team daily on any issues such as blocking or product increase/decreases within the most used trackers. If you’re ever running any analysis with EDITED and spot that something doesn’t look right or in line with what you would expect, please reach out to support@edited.com directly, with a URL link to the workbook you were analyzing. We can then investigate this for you!
2. Making Sense Of The Data
Once the data is collected, it must be ‘translated’ into a user-friendly format. To ensure consistency, all sites are translated into English when they come into the platform.
EDITED uses Artificial Intelligence and machine learning to help identify patterns in data that can work to inform insightful analysis. The ‘supervised’ machine learning method uses a set of labeled examples that have been manually created by specialists, to generalize and apply to all of the data.
For more information on Machine Learning, click here
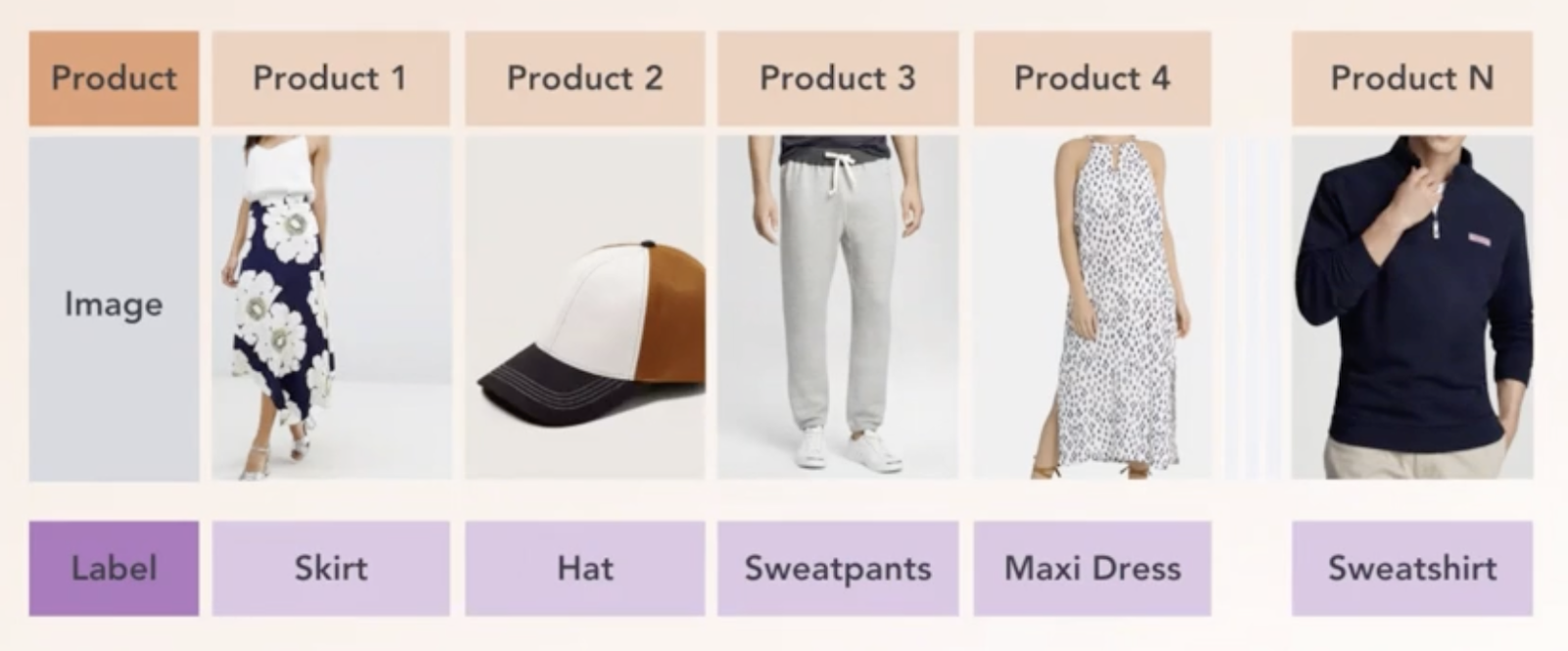
The machine-learning algorithm then learns from these labels until it is able to predict the label for what it is seeing.

Our model is trained only on text, not images, which means that it relies on common words and phrases associated with particular item types to identify the product. In the example below, a variety of descriptors are picked up by the model which, when read all together, help the model to understand that this product falls into the ‘Bottoms’ category, and is more specifically a pair of jeans.

While our models have an over 95% accuracy rate, mistakes can still happen! If you spot a product classified incorrectly, you can help our model learn by updating this directly within the product card. Simply hover over the category detail in question and select the ‘X’ next to ‘Is this correct?’ You can then select from the drop-down the category you believe this product should fall under, which will be run through our data pipe for QA feedback. For more information on manually curating categories, click here.
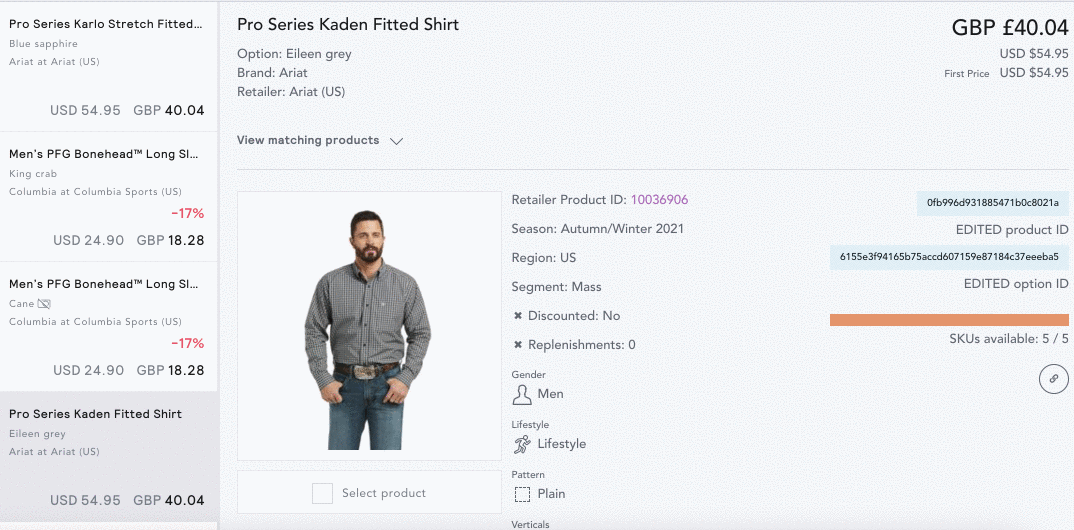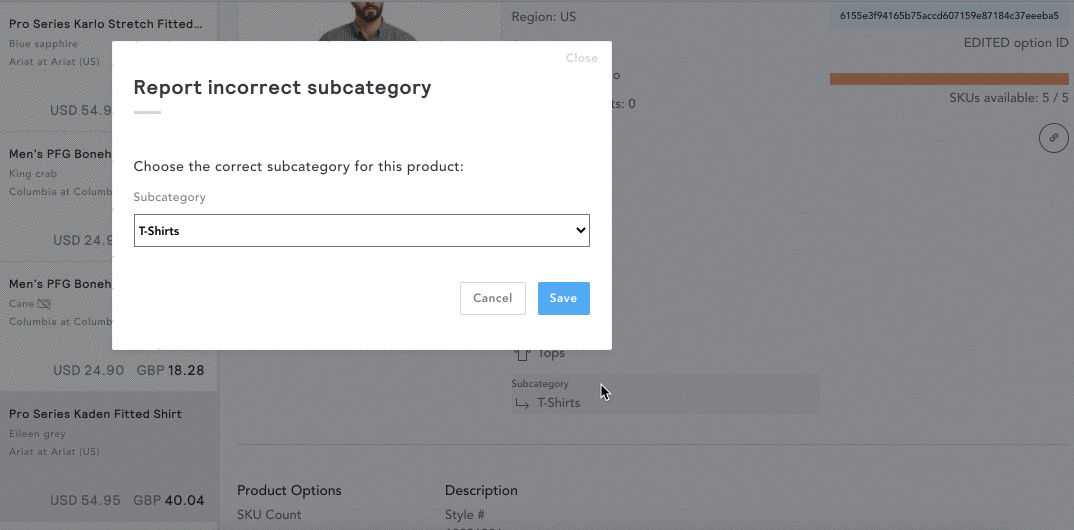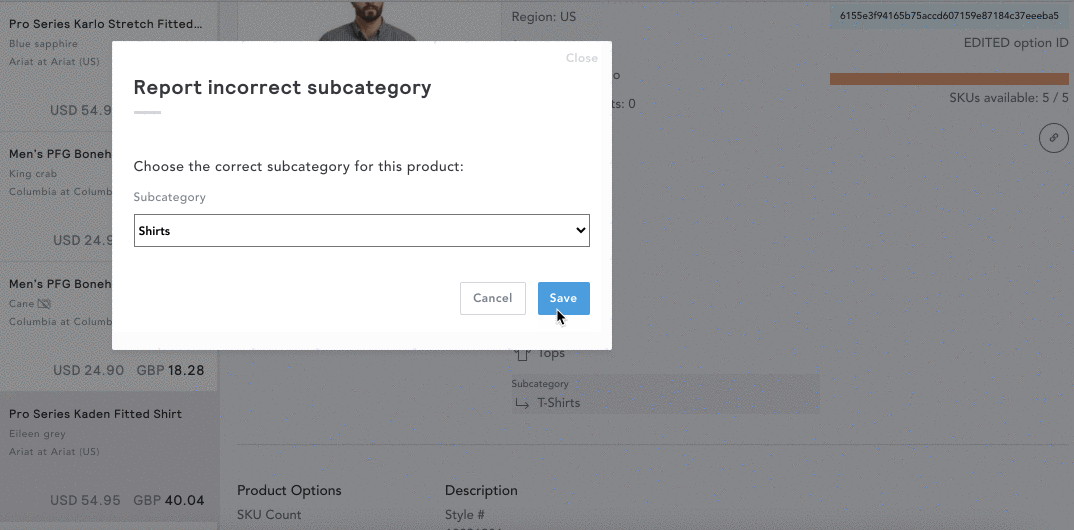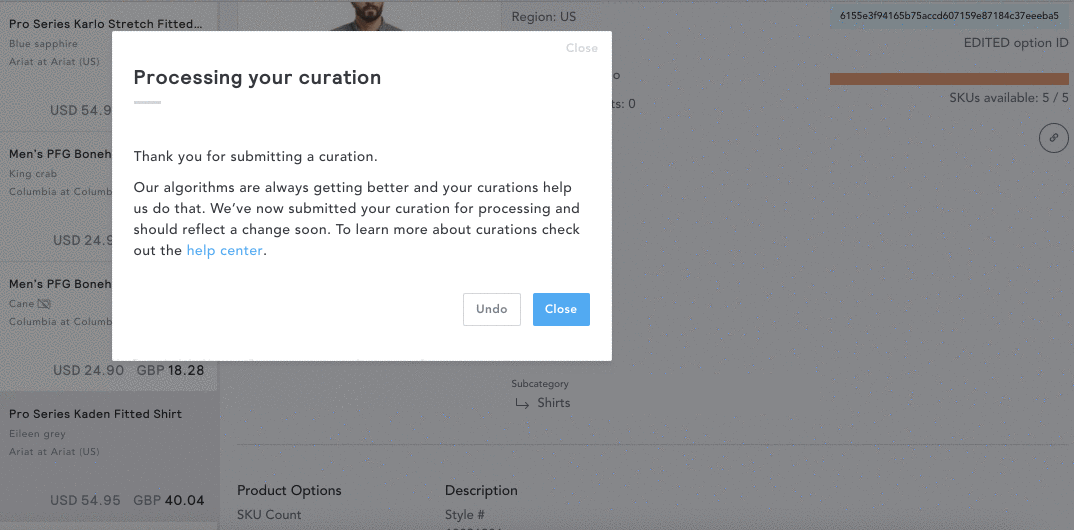
The normalization and classification process ensures consistency, as data is coming from a large variety of websites that all name their products differently. Color and sizing descriptions can also vary greatly. Within EDITED we are constantly quality assuring our normalized data and value feedback to ensure accuracy.
For example, within EDITED, you can analyze all "midi" dresses together regardless of how retailers describe or classify that product on their own site. We monitor dozens of languages and even the colloquialisms within the English language.
While the below product may be called “leggings” in the US, some European markets might call them “tights.” The normalization and classification process takes both of these product names into account and places them into the appropriate category so they can be compared together.

For further information regarding what products fall into specific categories within EDITED and how we categorize these, see Category Terminology.